Python笔记
Python笔记
一、注释
注释仅仅作为解释代码用 不会被程序所解析
1.单行注释
#在开头 那么这一行都是注释
#在中间 #后都是注释
2.多行注释
""" """
''' '''
3.标识符的命名规则
(1).字母、数字、下划线组成
2.开头不能是数字、也不能下划线开头(下划线开头 ->定义函数 私有)
3.不能使用关键字
4.严格区分大小写
4.输入与输出
输出: print() 向控制台输出数据
输入: input() 接收用户在键盘上输入的值
input(" ") 仅仅作为提示用户 没有其他任何用途
二、Python中的数据类型
2.1 数字类型
Python 中有两种常见数字类型,整型(int)和浮点型(float),整型数之间运算结果为整型,整型与浮点型之间运算结果为浮点型。除法永远返回浮点型。
布尔(bool)也属于数字类型。
2.2 字符串
2.2.1 字符串的创建与使用
字符串可以通过单引号(')或者双引号(")来表示,反斜线(\)来转译字符。字符串是常量,即不可改。
'spam eggs' # 单引号创建字符串
"doesn't" # 双引号创建字符串
''与""创建的字符串是一样的,但是他们不可以混用,如: '测试" ps:这是错误示范,千万不要记错
我们可以通过 """...""" 和 '''...''' 来表示多行字符串,在多行字符串中每一行末尾的换行符会被保留。如果我们想去除某一行默认的换行符,可以在行末加一个反斜线。
通过数字和乘机符号,我们可以对字符串进行重复。
print(3 * '张' + '益豪')
#输出结果 '张张张益豪'
两个相邻的字符串字面量可以直接拼接成一个新的字符串,但是字符串字面量和变量之间不行。
print('Py' 'thon')
#输出结果 'Python'
2.2.2 转义字符
通常情况下,反斜线会被作为转译字符使用,如果我们要强制将其作为一般字符时,需要在字符串前面加一个 r 标记,表示这个字符串使用原始字符。
以下是python中的大部分转义字符(看看就好,大部分用不到。只需要记住\r \n \t)
\n:换行
\r:回到行首
\t:表示一个空格
\\:表示\
\':表示'
\":表示"
\000,\00,\0:表示空格
r:原字符,在存在转义字符的字符串前输入 r / R ,则转义机制失效,打印包括转义字符的所有内容。
\:换行符
\0xx:表示对应 ASCII表字符,xx为两位数八进制数
\xyy:表示对应 ASCII表字符,yy为两位数十六进制数
\zzz:表示对应 ASCII表字符,zzz为三位数八进制
\a:震铃
\b:退格
\f:换页符(Form Feed),它用于在输出中创建一个新的页面
\v:代表垂直制表符(vertical tab)。垂直制表符是一种控制字符,用于在文本中创建垂直间距。\uxxxx:表示对应汉字,xxxx指四位数的八进制数
2.3 列表
列表(set)由中括号创建,列表可以用来保存任意类型任意数量的元素,列表内的值可以改变。
列表的索引:
squares = [1, 4, 9, 16, 25]
squares[0] # 索引访问索引值0的位置,即数字1
squares[-1] # 索引访问索引值-1的位置,即数字25
squares[-3:] #将会返回新的列表[9, 16, 25]
通过 + 连接两个列表,可以返回一个新的列表:
squares + [36, 49, 64, 81, 100]
#返回 [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
我们可以通过索引对列表进行操作:
letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
['a', 'b', 'c', 'd', 'e', 'f', 'g']
# 替换一些值
letters[2:5] = ['C', 'D', 'E']
['a', 'b', 'C', 'D', 'E', 'f', 'g']
# 删除一些值
letters[2:5] = []
['a', 'b', 'f', 'g']
# 清空列表
letters[:] = []
列表还支持简写方式:
squares = [x**2 for x in range(10)]
等效于:
squares = []
for x in range(10):
squares.append(x**2)
#[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
更复杂一点的例子:
a = [(x, y) for x in [1,2,3] for y in [3,1,4] if x != y]
#[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
等效于:
a = []
for x in [1, 2, 3]:
for y in [3, 1, 4]:
if x != y:
a.append((x, y))
2.4 元组
元组(tuple)由小括号创建(括号省略同样可以创建,但不建议) ,元组可以存放任意类型任意数量的元素,元组内的值不能修改。
t = 12345, 54321, 'hello!'
t2 = tuple() # 创建空的元组
#t[0]值为12345
#元组t:(12345, 54321, 'hello!')
v = ([1, 2, 3], [3, 2, 1])
#元组v:([1, 2, 3], [3, 2, 1])
通过如下方式可以对元组进行解构:
x, y, z = t
#此时变量x,y,z的值分别为12345 54321 hello!
2.5 集合
集合(set)中保存的是一组无序且唯一的值。注意,空集合需要使用 set()来创建,因为用 {}创建的表示一个空字典(dict)。
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # 重复项已经被删除
#{'orange', 'banana', 'pear', 'apple'}
集合运算:
a = set('abracadabra') #a中实际的值{'a', 'r', 'b', 'c', 'd'}
b = set('alacazam')
a - b # 在 a 中但是不在 b 中的字母
{'r', 'd', 'b'}
a | b # 在 a 中或在 b 中的字母
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
a & b # 即在 a 中又在 b 中的字母
{'a', 'c'}
a ^ b # 在 a 或者 b 中,但又不同时在 a 和 b 中
{'r', 'd', 'b', 'm', 'z', 'l'}
与列表相似,集合也支持简写方式:
a = {x for x in 'abracadabra' if x not in 'abc'}
#{'r', 'd'}
集合的操作
2.6 字典
字典(dict)用于存储一组键值对。key 可以是任何不可变的数据,但key不能重复。
tel = {'jack': 4098, 'sape': 4139}
tel['guido'] = 4127 #可直接用"="号添加新数据
#{'jack': 4098, 'sape': 4139, 'guido': 4127}
tel['irv'] = 4127
#{'jack': 4098, 'sape': 4139, 'guido': 4127, 'irv': 4127}
可以通过 dict() 构造函数来创建字典:
dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
#{'sape': 4139, 'guido': 4127, 'jack': 4098}
dict(sape=4139, guido=4127, jack=4098)
#{'sape': 4139, 'guido': 4127, 'jack': 4098}
字典也支持简写形式:
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
扩展:
可迭代对象
可迭代对象就是能够一次返回一个成员的对象,也就是可以 for…in 遍历的
所有的序列类型都是可迭代对象,如 list、str、tuple,还有映射类型 dict、文件对象等非序列类型也是可迭代对象
判断可迭代对象的函数:isinstance(Ls,Iterable) ->bool
Is=[3,1,45]
print(isinstance(Is,Iterable))
进制转换
二进制:bin() ->0B 0b
八进制:oct() ->0O 0o
十进制:int() ->0X 0x
十六进制: hex() ->0X 0x
数据转换
1.int( n ) 将n转换为 整数类型
2.float( n ) 将n转换为 浮点类型
涉及到字符串类型转换时:
字符串类型 不可以参与数学运算 + - * /
数字字符串(阿拉伯数字) 才可以进行转换
混合运算
1.整型和浮点型进行运算时 先把整型换算为浮点型
运算符
+-/ *加减乘除
/ 不取整
// ->整除
a1=5
b1=2
print(a1 // b1) # 2
print(a1 / b1) # 2.5
% 两数相除 取余数
** 次方 a**b a的b次方
赋值: = 比较是否相等 ==
1.同时赋值:
a2=b2=c2=1
2.多个赋值
a3,b3,c3=1,'物联',2301
复合赋值运算符
海象运算符:在表达式内部 赋值
:=
一般写法:
a = 15
if a > 10:
print('hello, walrus operator!')
海象运算符:
if a := 15 > 10:
print('hello, walrus operator!')
比较运算符
or and not
或 与 非
in not in
在 不在
位移运算符-> 二进制
and 同真为真 一假则假
or 一真为真 全假则假
运算符优先级
1.指数运算符
2.~按位翻转,+正号,-负号
3.*乘法,/除法,%取模,//取整除
4.+加法,-减法
5.右移,<<左移
6.&位与
7.^位异或,|位或
8.<=小于等于,<小于,>大于,>=大于等于
9.==等于,!=不等于
10.=赋值 %=取模赋值 /=除法赋值 //=取整除赋值 -=减法赋值 +=加法赋值 *=乘法赋值 **=指数赋值
11.is身份运算符,is not非身份运算符
12.in成员运算符,not in非成员运算符
13.not逻辑非,or逻辑或,and逻辑与
三、流程控制语句与运算符的优先级
3.1 if 语句
# if 判断条件1:
# 代码段1
# elif 判断条件2:
# 代码段2
# else:
# 代码段
#例
if x < 0:
print('x小于0')
elif x == 0:
print('Zero')
else:
print('x大于0')
elif 就是 else if 的含义
3.2 for 语句
Python 中的 for 循环只能针对具备迭代能力(iterable)的类型(比如列表、字符串等)进行循环。
for循环语句格式
for 临时变量 in 目标对象:
代码段
range(start,end)
#start(包含stard)到(end-1)
扩展:可迭代对象
支持通过for…in…语句迭代获取数据的对象就是可迭代对象。
3.3 while 语句
只要 while 语句中的表达式为 True,循环就会一直持续下去。
while 循环条件:
代码段
3.4 break 、continue 和循环中的 else 语句
与其他语言(如 C 语言)相同,break 语句用于跳出当前循环,continue 语句用于跳出本次循环直接进入下一次循环逻辑。
for n in range(2, 10):
for x in range(2, n):
if n % x == 0:
print(n, '等于', x, '*', n//x)
break
else:
print(n, '是个素数')
2 是个素数
3 是个素数
4 等于 2 * 2
5 是个素数
6 等于 2 * 3
7 是个素数
8 等于 2 * 4
9 等于 3 * 3
循环中的 else 分支只有在循环结束且不是 break 退出的时候才会执行。else 既可以与 for 一起使用,也可以与 while 一起使用。
for num in range(2, 3):
if num % 2 == 0:
print("偶数", num)
continue
print("奇数", num)
偶数 2
奇数 3
pass 语句
pass 语句什么也不做,可以用来定义一个空类或者空函数。
def MyEmptyClass:
pass
这样就定义了一个空的函数,pass语句什么都不会做,只是让这个空函数或类创建出来不会报错
简单的说就是函数或类不能是空的,空的就会报错。放一个pass里面就有了内容不会报错。
逻辑判断和优先级
(一)比较运算符 in 和 not in 可以判断一个值是否在序列中。比较运算符 is 和 is not 可以判断两个对象是否是同一个对象。所有的比较运算符优先级相同,但是都比数值运算符优先级低。
(二)运算符可以级联,比如 a < b == c 表示 a 小于 b 同时 b 等于 c。
(三)可以使用布尔运算符 and 和 or 组合比较,并且比较(或任何其他布尔表达式)的结果可以用 not 否定。布尔运算符的优先级比比较运算符低,在布尔运算符中,not 的优先级最好,or 的优先级最低。因此, A and not B or C 与 (A and (not B)) or C 等同。
(四)and 和 or 同时也是短路求值运算符,从左到右依次求值,当满足结果时就中断求值。即如果 A 和 C 都是 True 但是 B 是 False,那么 A and B and C 的值为 False,不管 C 的值是什么。本条较为高深,可以不掌握!!!
我们可以将比较结果赋值给一个变量:
string1, string2, string3 = '', 'str1', 'str2'
non_null = string1 or string2 or string3
'''
这一行代码使用了逻辑或运算符 or。在Python中,or 运算符从左到右逐个检查操作数。
首先检查 string1 的值,由于 string1 是空字符串(在布尔上下文中等同于 False),所以继续检查下一个。
然后检查 string2 的值,string2 是 'str1'(在布尔上下文中等同于 True),因此 non_null 的值被赋予 'str1',后面的 string3 将不再被检查。
'''
在 Python 中,我们还可以对序列进行比较。这种比较使用字典顺序:首先比较前两项,如果它们不同,则决定比较的结果;如果它们相等,则比较接下来的两个项目,依此类推,直到用完任一序列。如果要比较的两个项目本身是相同类型的序列,则递归地进行字典序比较。如果两个序列的所有项比较相等,则认为这两个序列相等。如果一个序列是另一个的初始子序列,则较短的序列是较小(较小)的序列。字符串的字典顺序使用 Unicode 代码点编号来对单个字符进行排序。
相同类型序列之间比较的一些示例:
(1, 2, 3) < (1, 2, 4)
[1, 2, 3] < [1, 2, 4]
'ABC' < 'C' < 'Pascal' < 'Python'
(1, 2, 3, 4) < (1, 2, 4)
(1, 2) < (1, 2, -1)
(1, 2, 3) == (1.0, 2.0, 3.0)
(1, 2, ('aa', 'ab')) < (1, 2, ('abc', 'a'), 4)
请注意,在 Python 中如果对象具有适当的比较方法,则使用 < 或 > 比较不同类型的对象也是合法的。如果对象没有定义比较方法,则会抛出 TypeError 错误。
四、格式化字符串
4.1 %格式化字符串
- % ->占位符 提前占着位置 等待后续数据
format % values
print("我今年%d岁" % 18)
format values
#举例
str_2 = "物联2301班%s今年%d岁!" % ('王俊辉', 18)
print(str_2)#输出:物联2301班王俊辉今年18岁
Python中常见格式符
%c 字符
%s 通过str() 字符串转换来格式化
%i 有符号十进制整数
%d 有符号十进制整数
%u 无符号十进制整数
%o 八进制整数
%x 十六进制整数(小写字母)
%X 十六进制整数(大写字母)
%f 浮点实数
下方是额外补充
%e 索引符号(小写'e')
%E 索引符号(大写“E”)
%g %f和%e 的简写
%G %f和%E的简写
4.2 使用format方法格式化字符串
format方法格式
str1 = 'My name is {}'
print(str1.format('张益豪'))#将输出My name is 张益豪
str2 = 'My name is {},I am {}.'
print(str2.format('张益豪',18))#将输出My name is 张益豪,I am 18.
#同样可以用下面这样的写法
name = "张益豪"
age = 18
str3 = 'My name is {name},I am {age}.'
print(str3.format(name=name,age=age))
#还可以指定替换浮点型的精度
p = 19
t = 22
print("所占百分比{:.2}".format(p/t)) #意味着只会保留两位小数。
4.3 使用f-string 格式化字符串
格式
age = 18
name = 杨玉东
f('我是{name},我{age}岁了')#输出:我是杨玉东我18岁了
使用format与f-string方法不需要考虑数据类型。
4.4 字符串的常见操作
4.4.1 字符串查找
#格式:str.find(sub, start, end)
#查找 ->sub:要查找的字符 start 查找的开始范围 end 结束范围
str_5 = "物联230123012301班王俊辉今年28岁!"
print(str_5.find('王')) # 将返回15,意味着在索引15的位置是我们想要查的字符王
4.4.2 字符串替换
#格式 str.replace(old, new, count)
#替换 -> old:老字符串 new:新字符串 count:替换最大次数
print(str_5.replace('2301', '2302', 2))#将2301替换成2302两次
4.4.5字符串的分割与拼接
分割
#格式 str.split(sep, maxsplit)
#分割 ->sep:分隔符 maxsplit:最大分割次数
print(str_5.split('2', 1)) #['物联', '30123012301班王俊辉今年28岁!']
#分割后你的分隔符会被移除
拼接
#格式 str.join(str2)
#例子
str5 = '张益豪和'
str6 = '杨玉东一块打游戏'
print(str5.join(str6))#张益豪和杨玉东一块打游戏
#也可以直接使用+号拼接字符串
print(str5+str6))#张益豪和杨玉东一块打游戏
4.4.6 字符串删除指定字符
| 方法 | 语法格式 | 功能说明 |
|---|---|---|
| strip | str.strp([char]) | 删除字符串头部与尾部的指定字符 |
| lstrip | str.lstrp([char]) | 删除字符串头部的指定字符 |
| rstrip | str.rstrp([char]) | 删除字符串尾部的指定字符 |
4.4.7 字符串的大小写转化
| 方法 | 功能说明 |
|---|---|
| upper() | 将字符串中的小写字母全部转换成大写字母 |
| lower() | 将字符串中的大写字母全部转换成小写字母 |
| capitalize() | 将字符串中的第一个字母转换成大写形式 |
| title() | 将字符串中的每个单词的首字母转换成大写形式 |
4.4.8 字符串对齐
| 方法 | 语法格式 | 功能说明 |
|---|---|---|
| center | str.center(width[,fillchat]) | 返回长度为width的字符串,原字符串居中显示 |
| ljust | str.ljust(width[,fillchat]) | 返回长度为width的字符串,原字符串左对齐显示 |
| rjust | str.rjust(width[,fillchat]) | 返回长度为width的字符串,原字符串右对齐显示 |
五、组合数据类型
5.1 列表
5.1.1 列表的创建
列表的创建方式非常简单,既可以直接使用中括号“[]”创建,也可以使用内置的list()函数快速创建
list_one=[] #使用[]创建空列表
li_two=list() #使用list()创建空列表
5.1.2 列表元素的访问
list_one=["Java","C#","Python","PHP"]
print(list_one[1]) #访问索引1位置的元素
5.1.3添加列表元素
list_one=["Java","C#","Python","PHP"]
append方法
list_one.append("C++")
#append方法用于在列表末尾添加新元素
extend方法
list_one.extend([["Android","IOS"])
#extend方法用于在列表末尾添加另一个列表中的所有元素
insert方法
list_one.insert(2,“HTML")
#按照索引将元素插入列表的指定位置
5.1.4元素排序
li_one=[6,2,5,3]
sort() 方法
list_one.sort()
#有序的元素会覆盖原来的列表元素,不产生新列表
reverse() 方法
li_two=sorted(li_one)
#产生排序后的新列表,排序操作不会对原列表产生影响
sorted() 方法
li_one.reverse()
#逆置列表,即把原列表中的元素从右至左依次排列存放
5.1.5 删除列表元素
li_one=[6,2,5,3,3]
del语句
delli_one[0]
#删除列表中指定位置的元素
remove()方法
li_one.remove(3)
#移除列表中匹配到的第一个元素
pop()方法
li_one.pop()
#移除列表中的某个元素,若未指定具体元素,则移除列表中的最后一个元素
clear()方法
li_one.clear()
#清空列表
5.2 元组
元组使用()构建,还可以使用内置函数tuple()构建元组。
t1=() #使用()构建元组
t2=tuple() #使用tuple函数构建元组
使用圆括号“()”创建元组时,如果元组中只包含一个元素,那么需要在该元素的后面添加逗号,从而保证Python解释器能够识别其为元组类型。否则会被判定为字符串数据。
元组支持以索引和切片方式访问元组的元素,也支持在循环中遍历元组。
tuple_demo=('p','y','t','h','o','n')
tuple_demo[2]
#使用索引
tuple_demo[2:5]
#使用切片
for i in tuple_demo:
print(i)
#使用遍历的方式访问元组
5.3 集合
5.3.1 创建集合
Python的集合(set)本身是可变类型,但Python要求放入集合中的元素必须是不可变类型。大括号“{}”或内置函数set()均可构建集合。
s1={1} #使用{}构建集合
s2=set([1,2]) #使用set构建元组
注意,使用{}不能创建空集合(不包含元素的{}创建的是字典变量),空集合只能利用set()函数创建。
5.3.2 操作集合的常见方法
| 常见操作 | 说明 |
|---|---|
| S.add(x) | 向集合S中添加元素x,x已存在时不做处理 |
| S.remove(x) | 删除集合 S 中的元素x,若x不存在则抛出KeyError 异常 |
| S.discard(x) | 删除集合S 中的元素x,若x不存在不做处理 |
| S.pop() | 随机返回集合S中的一个元素,同时删除该元素。若S为空,抛出KeyError 异常 |
| S.clear() | 清空集合 S |
| S.copy() | 拷贝集合S,返回值为集合 |
| S.isdisjoint(T) | 判断集合S和T中是否没有相同的元素,没有返回Tnue,有则返回 False |
5.3.3 集合推导式
集合也可以利用推导式创建,集合推导式的格式与列表推导式相似,区别在于集合推导式外侧为大括号“{}”,具体如下:
a = {exp for x in set if cond}
例子:使用集合推导式在列表ls的基础上生成只包含偶数的元素集合
ls = {1,2,3,4,5,6,7,8}
s = {date for date in ls if date%2==0} #新的集合s将只有ls中偶数元素
5.4 字典
5.4.1创建字典
字典的表现形式为一组包含在大括号“{}”中的键值对,每个键值对为一个字典元素,每个元素通过逗号“,”分隔,每对键值通过“:”分隔,除了使用“{}”创建字典还可以使用内置函数dict创建字典。
字典元素无序,Key必须唯一
d1={'A':123,12:'python'} #使用{}构建集合
d2=dict({'A':'123','B':'135'}) #使用dict构建元组
5.4.2 字典的访问
字典的值可通过“键”或内置方法get()访问
d2=dict({'A':'123','B':'135'})
print(d2['A']) #输出123
keys()方法
d2.keys()
#获取所有键 [A,B]
values()方法
d2.values()
#获取所有值 [123,135]
items()方法
d2.items()
#获取所有元素 ['A':'123','B':'135']
5.4.3 字典元素的添加与修改
字典支持通过为指定的键赋值或使用update()方法添加或修改元素
d2['Java']=98 #通过键添加
d2.update(sco=98) #通过update添加
修改元素的操作与添加元素的操作相同。
5.4.4 字典元素的删除
pop():根据指定键值删除字典中的指定元素
popitem():随机删除字典中的元素
clear():清空字典中的元素
5.4.5 字典推导式
字典推导式外侧为大括号“{}”,且内部需包含键和值两部分,具体格式如下:
{new_key:new_valueforkey,valueindict.items()}
利用字典推导式可快速交换字典中的键和值
old_dict={'name':'Jack','age':23,'height':185}
new_dict={value:keyforkey,valueinold_dict.items()}
print(new_dict) #结果:{'Jack':'name',23:'age',185:'height'}
六、函数
6.1 定义函数
Python中使用关键字def来定义函数,其语法格式如下:
def 函数名([参数列表]):
函数体
[return语句]
6.2 调用函数
函数在定义完成后不会立刻执行,直到被程序调用时才会执行。
调用函数的格式
函数名([参数列表])
函数内部也可以调用其他函数,这被称为函数的嵌套调用。
6.3 函数参数的传递
定义函数时设置的参数称为形式参数(简称为形参),将调用函数时传入的参数称为实际参数(简称为实参)。函数的参数传递是指将实际参数传递给形式参数的过程。
6.3.1 位置参数的传递
函数在被调用时会将实参按照相应的位置依次传递给形参,也就是说将第一个实参传递给第一个形参,将第二个实参传递给第二个形参,以此类推。
6.3.2 关键字参数的传递
使用符号“/”来限定部分形参只接收采用位置传递方式的实参。
defconnect(ip,port):
print(f"设备{ip}:{port}连接!")
connect(ip="127.0.0.1",port=8080)
6.3.3 默认参数的传递
函数在定义时可以指定形参的默认值,如此在被调用时可以选择是否给带有默认值的形参传值,若没有给带有默认值的形参传值,则直接使用该形参的默认值。
def connect(ip,port=8080):
print(f"设备{ip}:{port}连接!")
connect(ip="127.0.0.1")
connect(ip="127.0.0.1",port=3306)
6.3.4参数的打包与解包
如果函数在定义时无法确定需要接收多少个数据,
那么可以在定义函数时为形参添加“*”或“**”:
“*”——接收以元组形式打包的多个值
“**”——接收以字典形式打包的多个值
用*解包元组
def test(a,b,c,d,e):
print(a,b,c,d,e)
#定义
nums=(11,22,33,44,55)
test(*nums)
#输出结果 11 22 33 44 55
用**解包字典
def test(a,b,c,d,e):
print(a,b,c,d,e)
#定义
nums={"a":11,"b":22,"c":33,"d":44,"e":55}
test(**nums)
#输出结果 11 22 33 44 55
6.3.5 混合传递
优先按位置参数传递的方式。
然后按关键字参数传递的方式。
之后按默认参数传递的方式。
最后按打包传递的方式。
在定义函数时:
带有默认值的参数必须位于普通参数之后。
带有“*”标识的参数必须位于带有默认值的参数之后。
带有"**"标识的参数必须位于带有“*”标识的参数之后。
6.4函数的返回值
函数中的return语句会在函数结束时将数据返回给程序,同时让程序回到函数被调用的位置继续执行。
def filter_sensitive_words(words):
if"山寨"inwords:
new_words=words.replace("山寨","**")
returnnew_words
result=filter_sensitive_words("这个手机是山寨版吧!")
print(result)
如果函数使用return语句返回了多个值,那么这些值将被保存到元组中。
6.5变量作用域
变量并非在程序的任意位置都可以被访问,其访问权限取决于变量定义的位置。变量的有效范围称为该变量的作用域。本节将对变量作用域的相关知识进行详细讲解。
6.5.1局部变量和全局变量
根据作用域的不同,变量可以分为局部变量和全局变量。下面分别对局部变量和全局变量进行介绍。
1.局部变量
局部变量是指在函数内部定义的变量,它只能在函数内部被使用,函数执行结束之后局部变量会被释放,此时无 法进行访问。
2全局变量
全局变量可以在整个程序的范围内起作用,它不会受函数范围的影响。例如,test.one0函数外定义了一个全局变量 number,分别在该函数内外访问全局变量 number,代码如下 :
number=10
def test one() :
print(number)
test one()
print(number)
#运行代码,结果如下所示:
10
结合代码运行结果进行分析,程序在执行 test_one0函数时成功访问了全局变量number.并且打印了number的值;程序在执行完test_one 函数后再次成功访问了全局变量number
注意:
在创建全局变量和全局函数时需顶格创建
在函数体内部只能访问全局变量,不能修改
6.5.2 global和nonlocal关键字
函数内部无法直接修改全局变量或在嵌套函数的外层函数声明的变量,但可以使用global或nonlocal关键字修饰变量以间接修改以上变量。本节分别介绍global和nonlocal关键字的用法。
1.global关键字
使用gobal关键字可以将局部变量声明为全局变量,其使用方法如下:
loba] 恋量
如此便可以在函数内部修改全局变量。下面对 6.5.1节的最后一个示例进行修改,先在test_one0函数中使用global关键字声明全局变量number,然后在函数中重新给number 赋值修改后的代码如下:
number =10
def test one():
global numbernumber +=1
print(number)
test one()
print(number)
2.nonlocal关键字
使用nonlocal关键字可以在局部作用域中修改嵌套作用域中声明的变量,其使用方法如下
nonloca 恋量假设有如下代码 :
def test():
number = 10
def test in():
nonlocal number
number =20
test in()
print(number)
test()
以上定义的 test0函数中嵌套了函数 test_in0test0函数中声明了一个变量number,而在 test_in0函数中使用nonlocal关键字修饰了变量number,并修改了number 的值,调用testin0函数后输出变量number 的值。
从程序的运行结果可以看出,程序在执行 test_in0函数时成功地修改了变量number,并且打印了修改后 number的值。
6.6 特殊形式的函数
6.6.1 递归函数
函数在定义时可以直接或间接地调用其他函数。若函数内部调用了自身,则这个函数被称为递归函数。递归函数通常用于解决结构相似的问题,它采用递归的方式,将一个复杂的大型问题转化为与原问题结构相似的、规模较小的若干子问题,之后对最小化的子问题求解从而得到原问题的解。
递归函数在定义时需要满足 2个基本条件:一个是递归公式,另一个是边界条件。其中递归公式是求解原问题或相似的子问题的结构;边界条件是最小化的子问题,也是递归终止的条件。
递归函数的执行可以分为以下 2个阶段
(1)递推: 递归本次的执行都基于上一次的运算结果
(2)回溯:遇到终止条件时,则沿着递推往回一级一级地把值返回来递归函数的一般定义格式如下所示 :
def 函数名 ([ 参数列表]):
if 边界条件:
return 结果
else:
return 递归公式;
6.6.2匿名函数
匿名函数是一类无须定义标识符的函数,它与普通函数一样可以在程序的任何位置使用。
Pvthon 中使用lambda 关键字定义匿名函数,它的语法格式如下:
lambda<形式参数列表> : <表达式>
结合以上语法格式可知,匿名函数与普通函数主要有以下区别。
(1)普通函数在定义时有名称,而匿名函数没有名称。
(2)普通函数的函数体中包含多条语句,而匿名函数的函数体只能是一个表达式
(3)普通函数可以实现比较复杂的功能,而匿名函数可实现的功能比较简单。
(4)普通函数能被其他程序使用,而匿名函数不能被其他程序使用。
定义好的匿名函数不能直接使用,最好使用一个变量保存它,以便后期可以随时使用这个函数。
七、文件与数据格式化
文件标识的意义:找到计算机中唯一确定的文件。
文件标识的组成:文件路径、文件名主干、文件扩展名。
D:\itcast\chapter10\example.dat
7.1 文件的基础操作
文件的打开、关闭与读写是文件的基础操作,任何更复杂的文件操作都离不开这些操作。
7.1.1 打开文件
内置函数open()用于打开文件,该方法的声明如下:
open(file,mode='r',buffering=-1)
'''
参数:
file:文件的路径。
mode:设置文件的打开模式,取值有r、w、a。
buffering:设置访问文件的缓冲方式。取值为0或1。
'''
| 打开模式 | 模式 | 描述 |
|---|---|---|
| r/rb | 只读模式 | 以只读的形式打开文本文件/二进制文件,若文件不存在或无法找到,文件打开失败 |
| w/wb | 只写模式 | 以只写的形式打开文本文件/二进制文件,若文件已存在,则重写文件,否则创建新文件 |
| a/ab | 追加模式 | 以只写的形式打开文本文件/二进制文件,只允许在该文件末尾追加数据,若文件不存在,则创建新文件 |
| r+/rb+ | 读取(更新)模式 | 以读/写的形式打开文本文件/二进制文件,若文件不存在,文件打开失败 |
| w+/wb+ | 写入(更换)模式 | 以读/写的形式打开文本文件/二进制文件,若文件已存在,则重写文件 |
| a+/ab+ | 追加(更新)模式 | 以读/写的形式打开文本/二进制文件,只允许在文件末尾添加数据,若文件不存在,则创建新文件 |
若open()函数调用成功,返回一个文件对象。
若待打开的文件不存在,文件打开失败,程序会抛出异常,并打印错误信息。
file1=open('E:\\a.txt')#以只读方式打开E盘的文本文件a.txt
file2=open('b.txt','w')#以只写方式打开当前目录的文本文件b.txt
file3=open('c.txt','w+')#以读/写方式打开文本文件c.txt
file4=open('d.txt','wb+')#以读/写方式打开二进制文件d.txt
7.1.2 关闭文件
Python可通过close()方法关闭文件,也可以使用with语句实现文件的自动关闭。
(1)close()方法
file.close()
(2)with()语句
with open('a.txt') as f:
pass
及时关闭文件是因为:
计算机中可打开的文件数量是有限
打开的文件占用系统资源
若程序因异常关闭,可能产生数据丢失
7.2 文件的读写操作
7.2.1.read()方法读取文件
read()方法可以从指定文件中读取指定字节的数据,其语法格式如下:
with open('file.txt',mode='r') as f:
print(f.read(2)) #读取两个字节的数据
print(f.read()) #读取剩余的全部数据
7.2.2.readline()方法读取文件
readline()方法可以从指定文件中读取一行数据,其语法格式如下:
withopen('file.txt',mode='r',encoding='utf-8') as f:
print(f.readline())
print(f.readline())
readlines()方法可以一次读取文件中的所有数据,若读取成功,该方法会返回
一个列表,文件中的每一行对应列表中的一个元素。语法格式如下:
readlines(hint=-1)
'''
参数hint的单位为字节,它用于控制要读取的行数
如果行中数据的总大小超出了hint字节,readlines()不会再读取更多的行。
'''
with open('file.txt',mode='r',encoding='utf-8') as f:
print(f.readlines())
read()(参数缺省时)和readlines()方法都可一次读取文件中的全部数据
7.2.3.write()写入方法
write()方法可以将指定字符串写入文件,其语法格式如下:
write(data)
#以上格式中的参数data表示要写入文件的数据,若数据写入成功,write()方法会返回本次写入文件的数据的字节数。
string = "Hereweareall,byday;bynight." #字符串
with open('write_file.txt',mode='w',encoding='utf-8') as f:
size=f.write(string)#写入字符串
print(size)#打印字节数
7.2.4.writeline()方法
writelines()方法用于将行列表写入文件,其语法格式如下:
writelines(lines)
以上格式中的参数lines表示要写入文件中的数据,该参数可以是一个字符串或者字符串列表。
string="Hereweareall,byday;\nbynightwe'rehurl'dBydreams,
eachoneintoaseveralworld."
with open('write_file.txt',mode='w',encoding='utf-8') as f:
f.writelines(string)
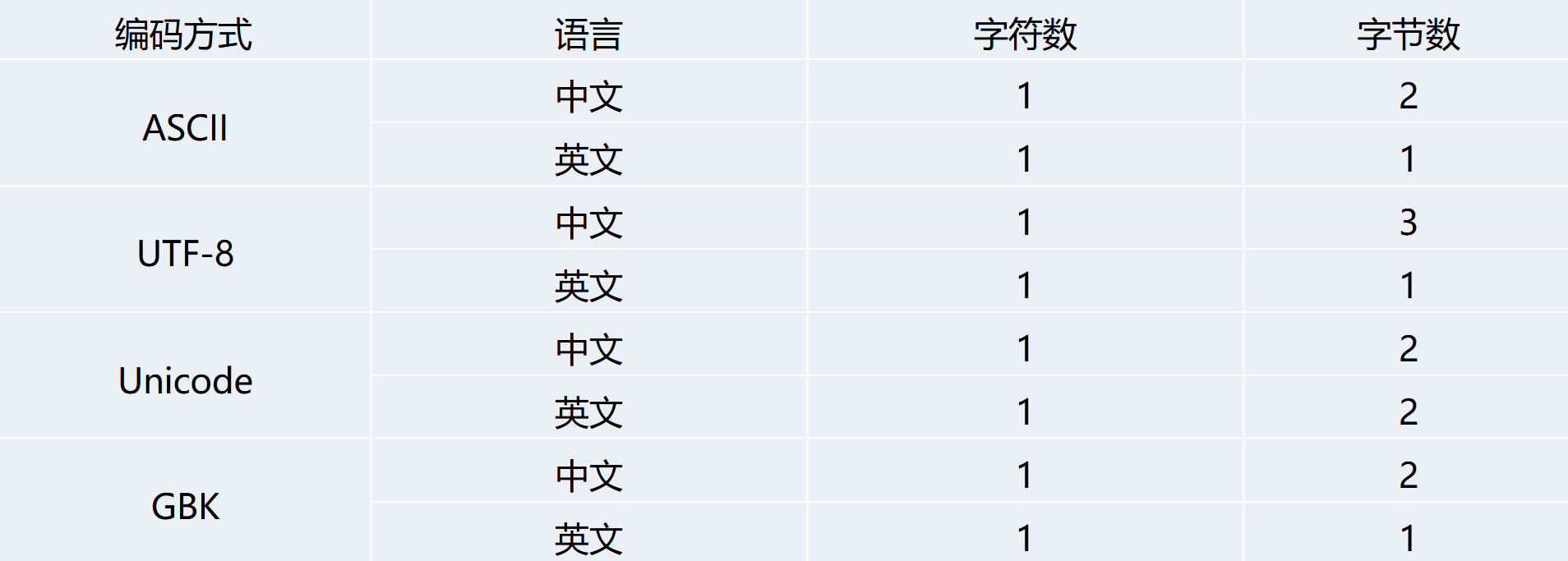
字符与编码
7.3文件定位读写
在文件的一次打开与关闭之间进行的读写操作是连续的,程序总是从上次读写的位置继续向下进行读写操作。
每个文件对象都有一个称为“文件读写位置”的属性,该属性会记录当前读写的位置。
文件读写位置默认为0,即在文件首部。
7.3.1 tell方法
tell()方法用于获取文件当前的读写位置,以操作文件file.txt为例,tell()的用法如下:
withopen('file.txt')asf:
print(f.tell())#获取文件读写位置
print(f.read(5))#利用read()方法移动文件读写位置
print(f.tell())#再次获取文件读写位置
7.3.2 seek方法
Python提供了seek()方法,使用该方法可控制文件的读写位置,实现文件的随机读写。seek()方法的语法格式如下:
seek(offset,from)
offset:表示偏移量,即读写位置需要移动的字节数
from:用于指定文件的读写位置,该参数的取值为0、1、2
0:表示文件开头。
1:表示使用当前读写位置。
2:表示文件末尾。
seek()方法调用成功后会返回当前读写位置。
withopen('file.txt') as f:
print(f.tell())#获取文件读写位置
print(f.read(5))#利用read()方法移动文件读写位置
print(f.tell())#再次获取文件读写位置